





Power Automate Desktopで、複数のWebサイトを自動巡回してスクリーンショットをキャプチャするフローのサンプルです。
フローの概要
事前に用意したURL(アドレス)の一覧を基にサイトを巡回し、一覧に記載されたすべてのサイトのスクリーンショットをキャプチャして画像に保存します。
使い方
フローとは別に、巡回を行うためのURLの一覧をテキスト形式で準備しておきます。下記のように、URLを各行に記載したテキストファイルを適当なフォルダに作ってください。
https://www.microsoft.com/ja-jp
...
...
...
...フローを実行するとファイルの選択ダイアログが表示されるので、URLのリストが記載されたファイルを指定します。その後は自動でブラウザが開き、それぞれのURLにアクセスして表示されたページの内容がPNG形式の画像で保存されます。
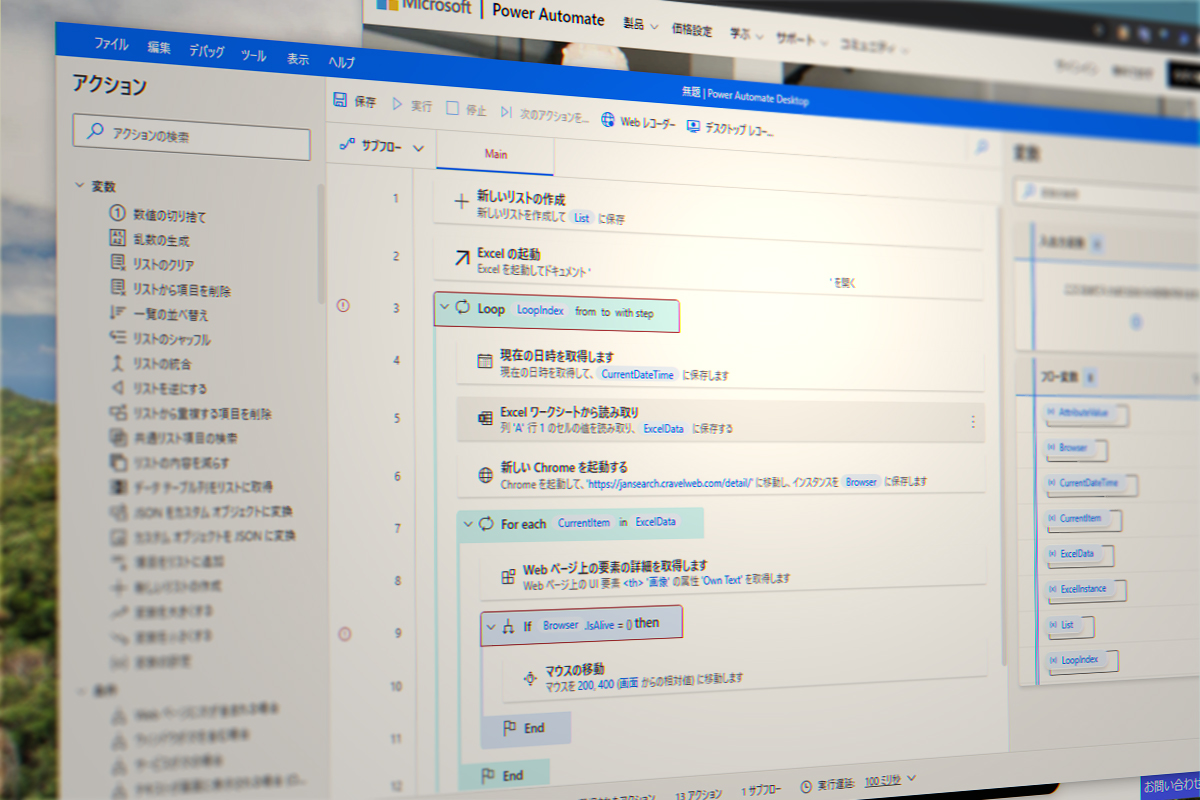
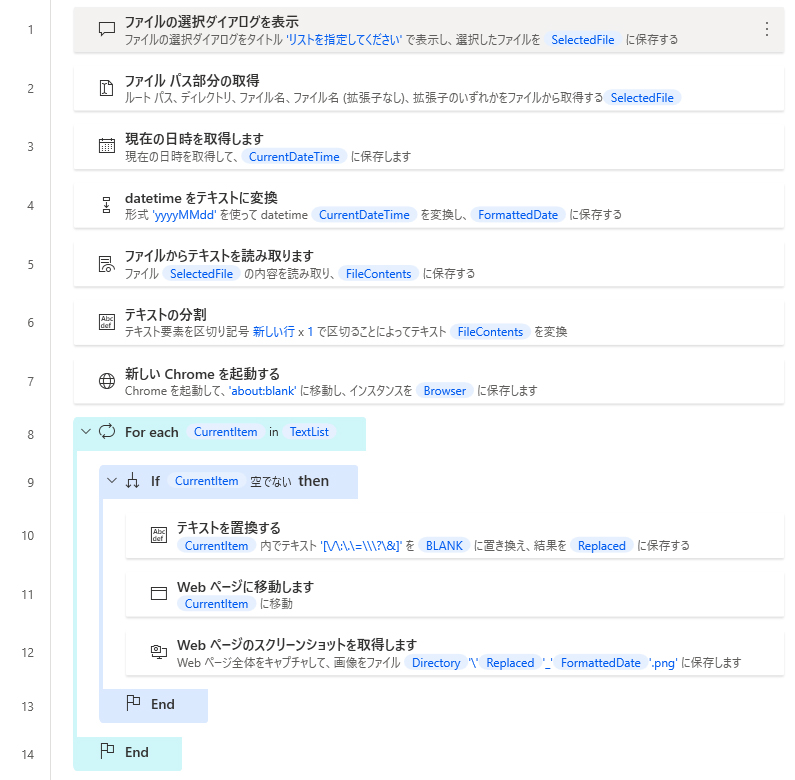
フロー内容
フロー一覧
作成したフローのスクリーンショットです。
コード
以下のコードをコピーし、Power Automate Desktopの編集画面に張り付けると上記のアクションをそのまま登録することができます。
Display.SelectFile Title: $'''リストを指定してください''' IsTopMost: False CheckIfFileExists: True SelectedFile=> SelectedFile ButtonPressed=> ButtonPressed2
File.GetPathPart File: SelectedFile RootPath=> RootPath Directory=> Directory FileName=> FileName FileNameWithoutExtension=> FileNameNoExtension Extension=> FileExtension
DateTime.Local DateTimeFormat: DateTime.DateTimeFormat.DateAndTime CurrentDateTime=> CurrentDateTime
Text.FromCustomDateTime DateTime: CurrentDateTime CustomFormat: $'''yyyyMMdd''' Result=> FormattedDate
File.ReadText File: SelectedFile Encoding: File.TextFileEncoding.UTF8 Content=> FileContents
Text.Split Text: FileContents StandardDelimiter: Text.StandardDelimiter.NewLine DelimiterTimes: 1 Result=> TextList
WebAutomation.LaunchChrome Url: $'''about:blank''' WindowState: WebAutomation.BrowserWindowState.Normal ClearCache: False ClearCookies: False BrowserInstance=> Browser
LOOP FOREACH CurrentItem IN TextList
IF IsNotEmpty(CurrentItem) THEN
Text.Replace Text: CurrentItem TextToFind: $'''[\\/\\:\\.\\=\\\\\\?\\&]''' IsRegEx: True IgnoreCase: False ReplaceWith: BLANK ActivateEscapeSequences: True Result=> Replaced
WebAutomation.GoToWebPage BrowserInstance: Browser Url: CurrentItem
WebAutomation.DataExtraction.TakeScreenshotSaveToFile BrowserInstance: Browser File: $'''%Directory%\\%Replaced%_%FormattedDate%.png''' FileFormat: WebAutomation.FileFormat.Png
END
ENDフロー設定のポイントなど
ファイルの選択とパスの取得
ファイルの取得は「ファイルの選択ダイアログを表示」アクションを使用しています。ここで選択したファイルは%SelectedFile%変数に格納され、その後「ファイルからテキストを読み取ります」アクションで内容を読み取っています。
そして、その内容を「テキストの分割」アクションを使ってリスト化し、「For each」アクションで繰り返し処理を行っています。
また、巡回して取得した画像は読み取ったテキストファイルと同じ場所に保存するように処理しています。これは「ファイル パス部分の取得」アクションに最初に取得した%SelectedFile%変数を渡すことで、%Directory%変数にパスのみが格納されるため、ファイルの保存場所の指定などに利用することが可能です。
補足:取得したパスの書式
「ファイルパス部分の取得」アクションや、「フォルダーの選択ダイアログを表示」アクションなどで取得したパスの情報は末尾に「\」記号が含まれていません。
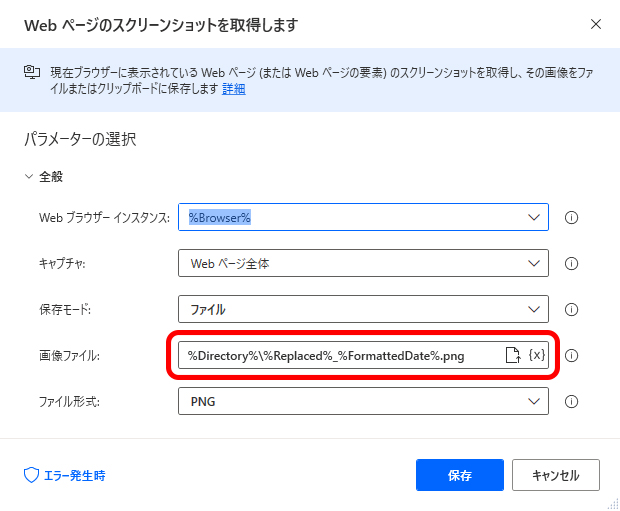
データをファイルに保存する場合などでパスとファイル名を組み合わせて指定するような場合は%Directory%\%FileName%のように、パスの区切り記号を適宜挿入して使用します。
日付の書式を加工する
今回のサンプルでは巡回して取得したサイトの画像のファイル名に現在の日付の情報を利用しています。
日時の書式を指定してテキストに変換するには「datetimeをテキストに変換」アクションを利用します。
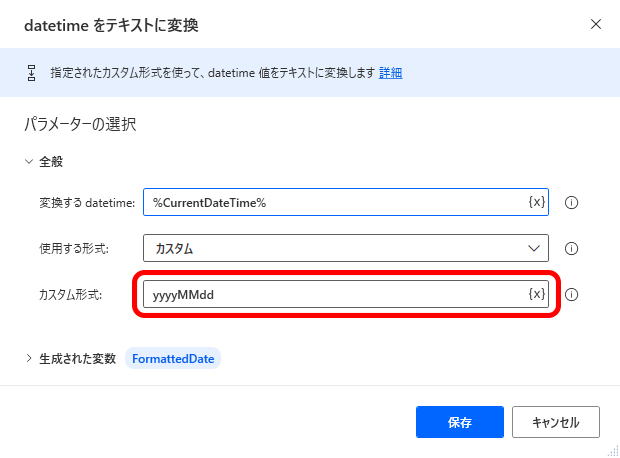
この [カスタム形式] で利用できる日時の書式については下記にもまとめてみたので参考にしてみてください。
テキストから記号を取り除く
また、今回巡回して取得したサイトの画像のファイル名に現在の日付の情報のほかにサイトのURLの情報も利用しています。
ファイル名にはサイトのURLで使用されているスラッシュ(/)やコロン(:)などの記号が使えアイため、それらの記号を取り除いた文字列を使用しています。
このテキストから記号を取り除くために「テキストを置換する」アクションを使っているのですが、記号を削除するような場合の指定方法はちょっとひと手間かける必要があります。
この解説については別途下記にまとめていますので、併せて参考にしてみてください。
Webページのキャプチャを画像ファイルに保存する
Webページのキャプチャを画像ファイルに保存するには「Webページのスクリーンショットを取得します」アクションを使用します。
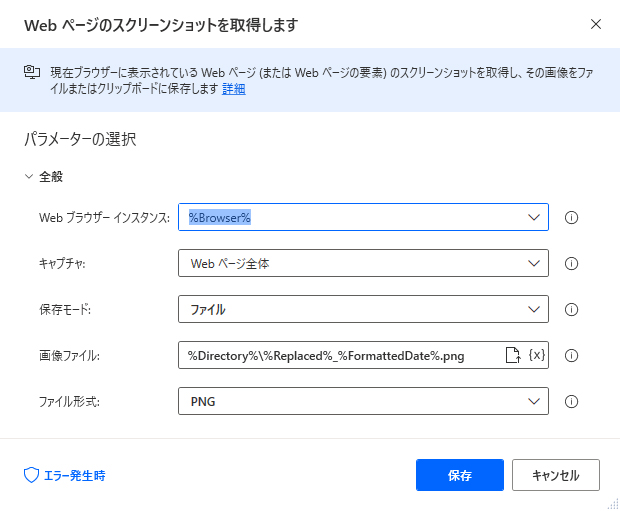
[画像ファイル] ボックスに保存するファイル名を指定するのですが、この時パスとファイル名を変数で指定してあげることで、「For each」の繰り返し処理などの中でファイル名を自動的に決定して保存させることが可能です。
画像の境界が途切れてしまう
なお、実際に今回のフローを使って取得したマイクロソフトのトップページのスクリーンショットは以下のようになっています。
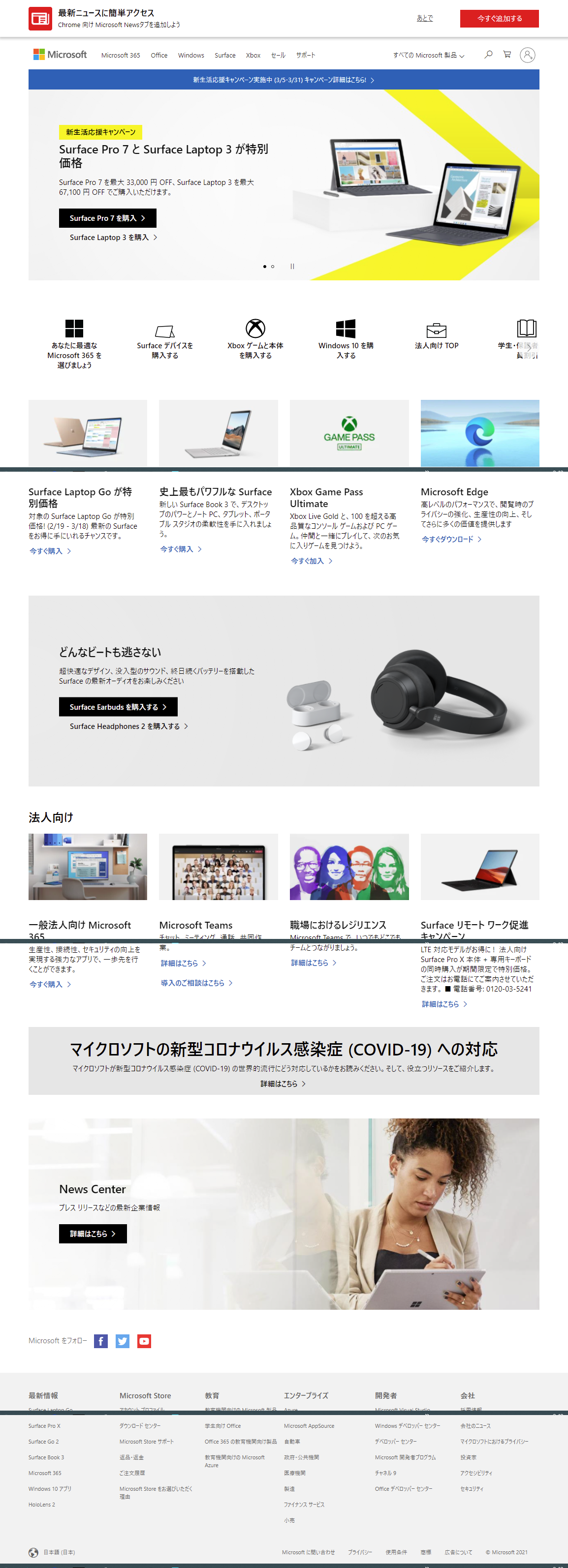
このアクションで取得できるスクリーンショットはページの表示中の部分だけでなく、ページの一番下まで自動的にスクロールして全体を収めるように加工されています。
ただ、今回の例では完全にきれいな画像にはなっておらず、スクリーンの境界線部分に太い水平線が入った状態になってしまいました。
また、場合によっては「接続中...」などのステータス表示もそのまま画像に入ってしまうこともありましたので、完全にきれいなキャプチャを取得するにはPower Automate Desktop側の改善が必要かもしれません。
コメント