



マイクロソフトのRPA(自動化ツール)である「Power Automate Desktop」を使ってウェブサイトを自動的に巡回してそのページに掲載されている表の内容をExcelに保存するフローのサンプルです。
これまでにもECサイトの在庫復活のチェックやサイトの画面キャプチャ取得など、Webサイトの自動巡回系のオートメーションのサンプルをご紹介してますが、今回のデータを取得してExcelに保存するようなフローも需要の高い例ではないかと思われます。
ここではPower Automate Desktopの基本的な設定方法や動作の中心となるアクションについて解説していますので、ぜひ参考に自動化にチャレンジしてみてください。
自動化フローの概要
事前に指定したアドレスのウェブサイトにアクセスし、そのページにあるテーブルからデータを取得します。
今回はサンプルとしてじゃん検索の価格比較ページにあるネット通販サイトの価格比較表を使ってExcelに取り込むフローを作っています。
今回のサンプルではアクセスするサイトを事前に決めていますが、テキストファイルにアドレスの一覧を用意して繰り返しアクションを使うことで、複数のサイトを自動巡回させるようなことも可能です。
テキストの一覧を基に複数のサイトを自動巡回させるフローについては以下を参考にしてみてください。
事前準備
ここで紹介している自動化フローを利用するには、マイクロソフトのWindows 10向け無料RPA(プロセス自動化)ツールの「Power Automate Desktop」が必要です。
また、ブラウザを使った自動巡回はGoogle Chromeを使って行っていますので、「Power Automate Desktop」のインストールと合わせて、Chrome向けのPower Automate Desktop拡張機能の導入も事前に行っておく必要があります。
「Power Automate Desktop」のインストールやChrome向けの拡張機能の導入など、基本的な導入と使い方については以下をご参照ください。
自動化フローの使い方
フローを実行すると自動的にブラウザが起動し、「新しいChromeを起動する」アクションで指定されたアドレスにアクセスします。
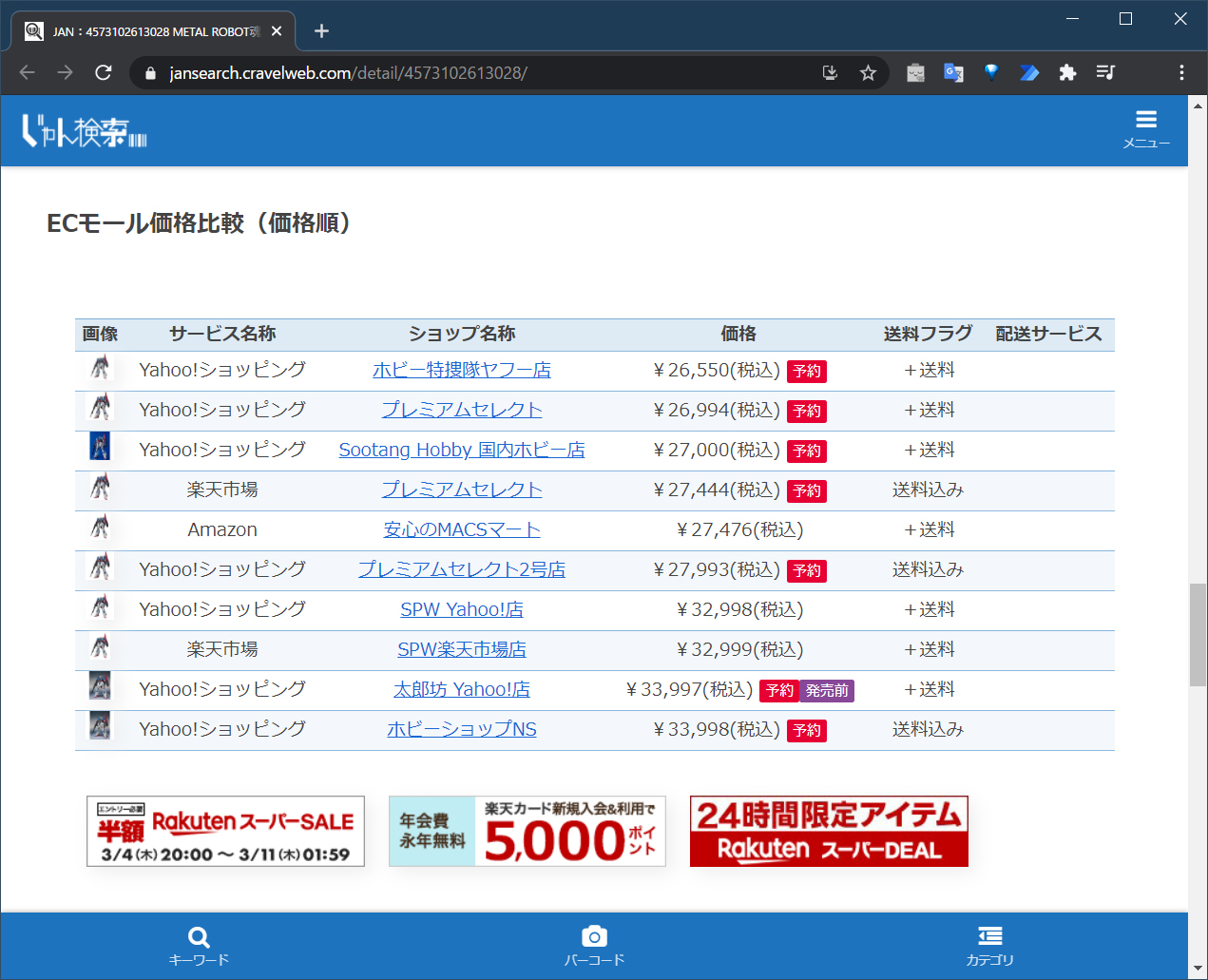
その後、ページの読み込みが完了したら、ページの中にある価格比較表のデータを取り込み、Excel形式のデータとして格納されます。
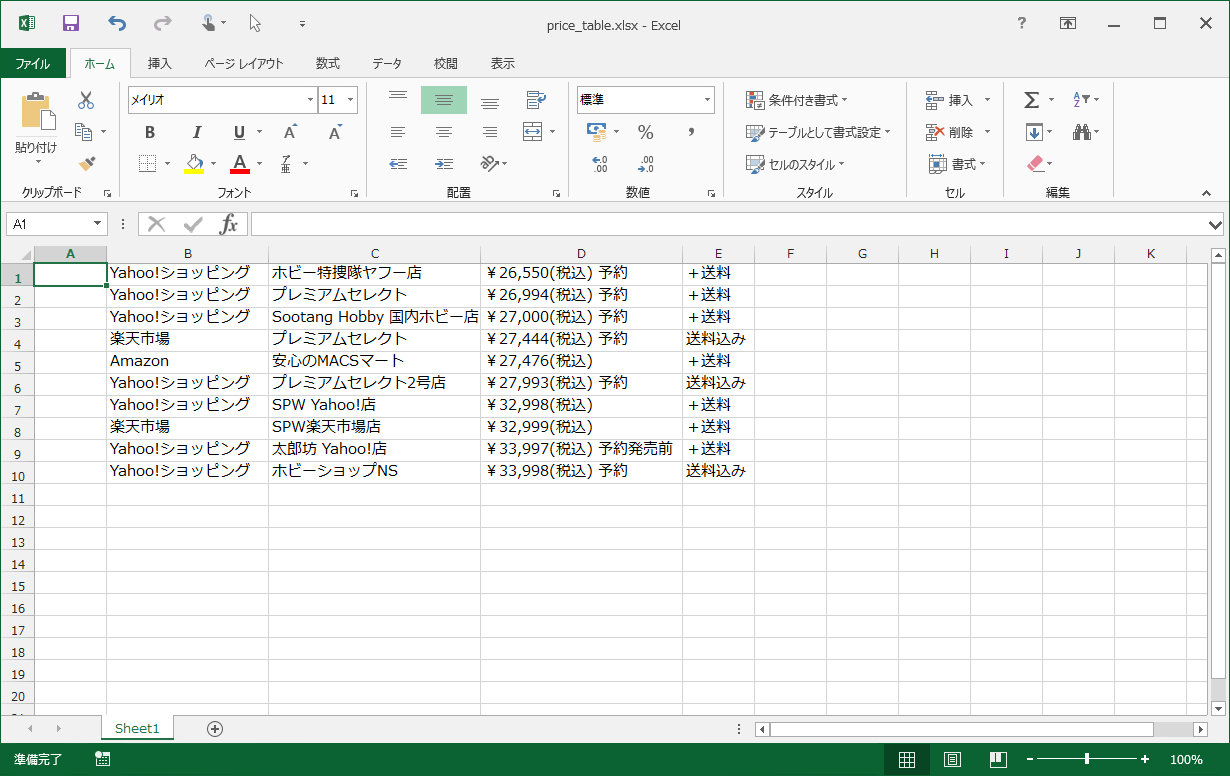
[ファイルを保存] ダイアログが表示されますので、ここでファイル名を指定するとその名前でエクセルのデータがxslx形式で保存されます。

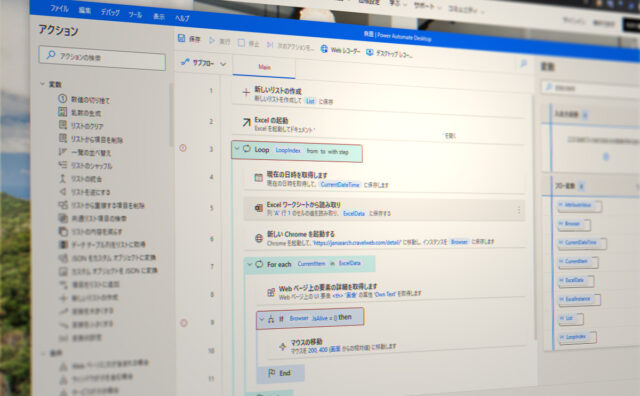
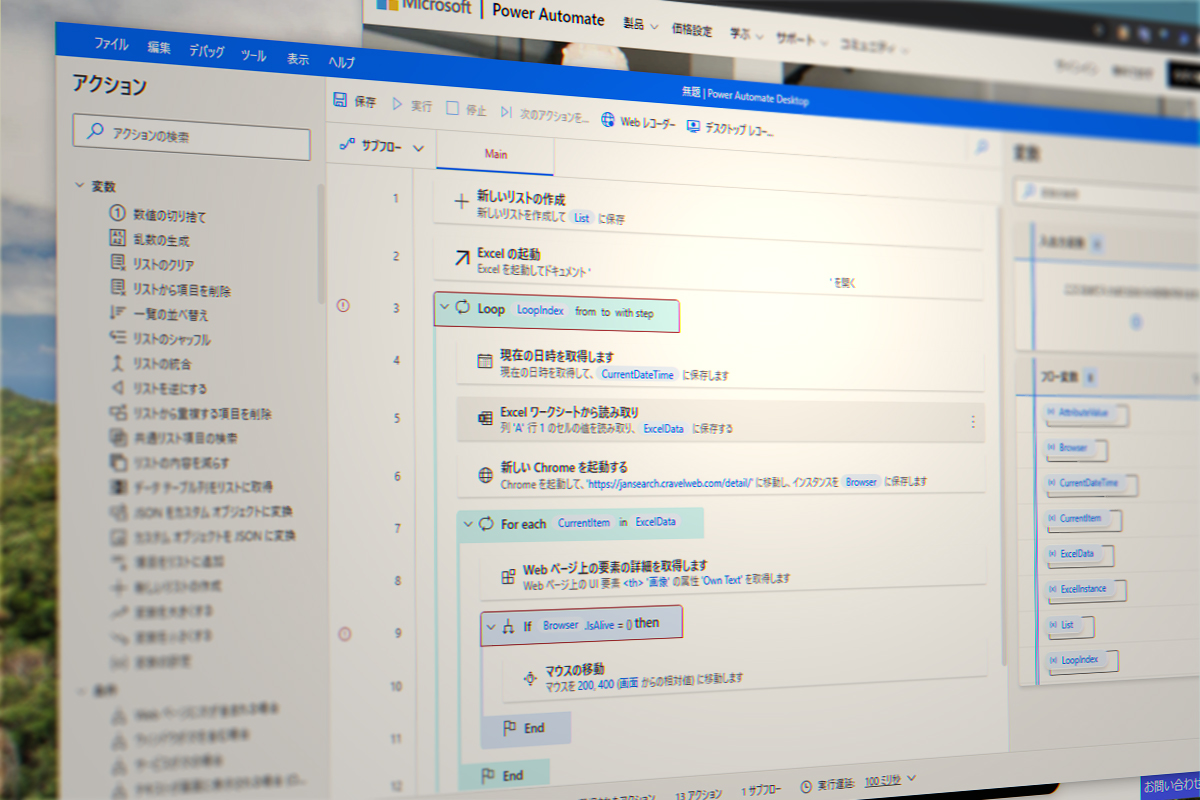
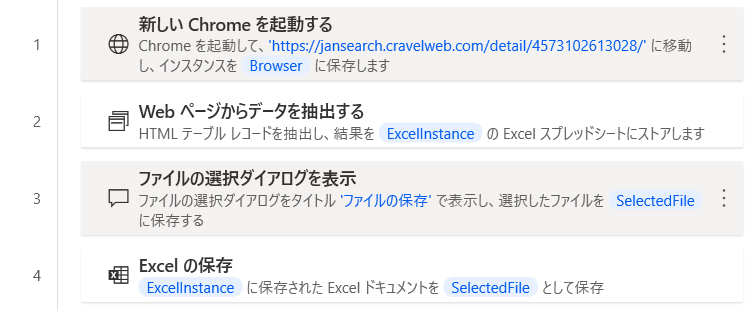
自動化フロー内容
フロー一覧スクリーンショット
作成したフローのスクリーンショットです。
Robin言語ソースコード
以下が、今回のサンプルのRobin言語ソースコードです。
コードをコピーし、Power Automate Desktopの編集画面に張り付けると今回のフローのアクションをそのまま登録することができます。
WebAutomation.LaunchChrome Url: $'''https://jansearch.cravelweb.com/detail/4573102613028/''' WindowState: WebAutomation.BrowserWindowState.Normal ClearCache: False ClearCookies: False BrowserInstance=> Browser
WebAutomation.DataExtraction.ExtractHtmlTableInExcel BrowserInstance: Browser Control: $'''html > body > div:eq(0) > div:eq(1) > div > main > article > div > div:eq(2) > table''' ExtractionParameters: {['画像', 'サービス名称', 'ショップ名称', '価格', '送料フラグ', '配送サービス'], ['', '', '', '', '', ''] } ExcelInstance=> ExcelInstance
Display.SelectFile Title: $'''ファイルの保存''' IsTopMost: False CheckIfFileExists: False SelectedFile=> SelectedFile ButtonPressed=> ButtonPressed
Excel.SaveAs Instance: ExcelInstance DocumentFormat: Excel.ExcelFormat.OpenXmlWorkbook DocumentPath: SelectedFileフロー設定のポイントなど
「Webページからデータを抽出する」アクションの設定
今回のフローでは「Webページからデータを抽出する」アクションを使ってWebページのデータを取り出しています。
このアクションはWebページに掲載されたスペック表などのフォーム、台帳や価格一覧のような帳票形式のデータを簡単に取り出すことができるアクションです。
特定のウェブサイトから取り出すデータを指定するには以下の手順を実施します。
Webページのテーブルから抽出データを指定する
「Webページからデータを抽出する」アクションの設定ウィンドウを開きます。
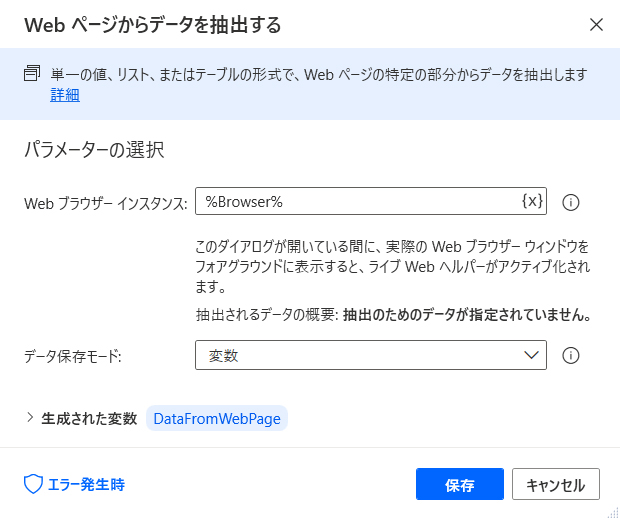
「Webページからデータを抽出する」ウィンドウが開いた状態でデスクトップに戻り、Chromeなどのブラウザを開いて対象のウェブページへアクセスします。
対象のページが表示されたら、取り込みたい表の上にマウスポインタを移動し右クリックします。次に、表示されたメニューから [HTMLテーブル全体を抽出する] をクリックします。
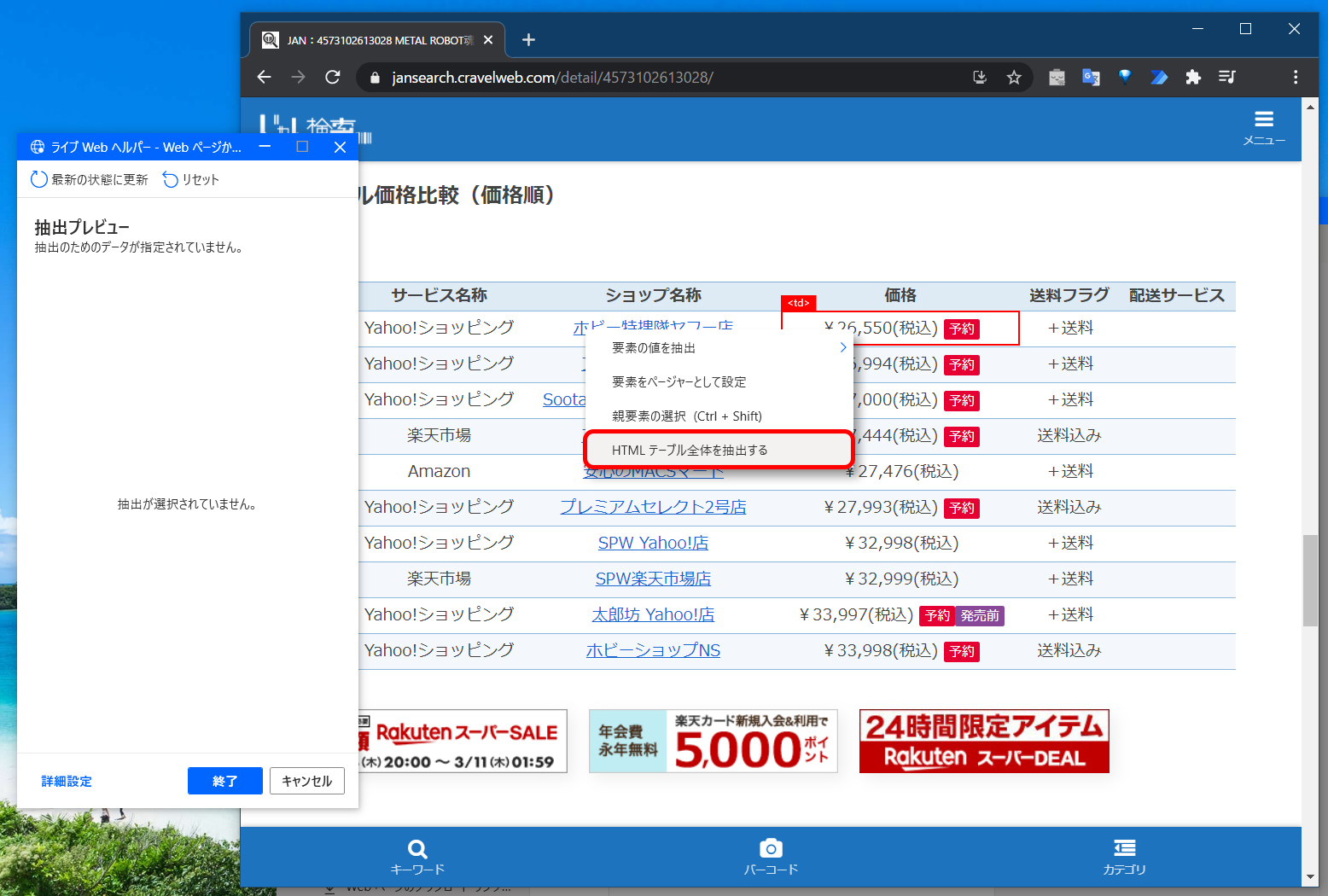
表全体が自動的に検出され、「ライブWebヘルパー」ウィンドウに表の内容がプレビュー表示されます。取得したい表が正しくプレビューに表示されない場合、[リセット] ボタンを押すと再度表の選択に戻ることができます。
抽出対象の表が問題なく表示されたら、[終了] ボタンをクリックして閉じます。
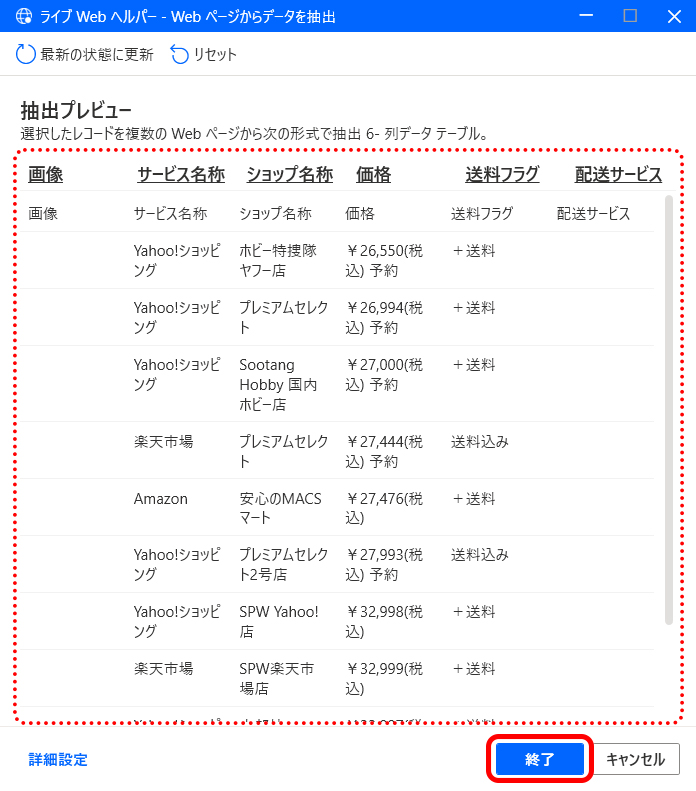
「Webページからデータを抽出する」ウィンドウに戻ると、「抽出されるデータの概要」エリアに先ほど指定したWebページの表の情報が反映されます。
次に、[データ保存モード] ボックスの一覧から「Excel スプレッドシート」を選択し、[保存] ボタンをクリックして閉じます。
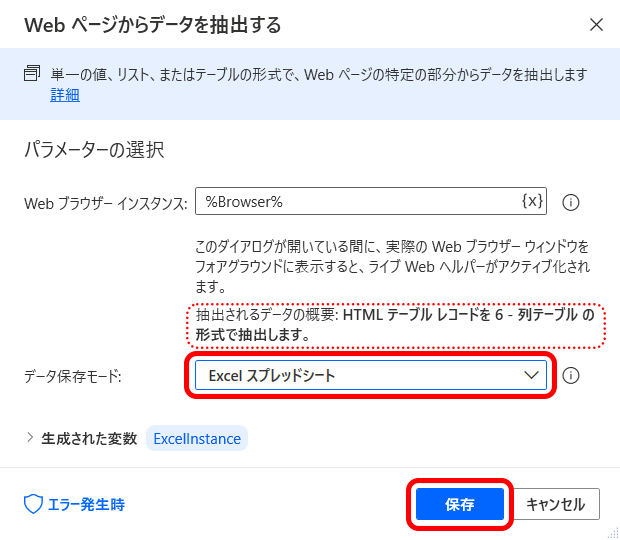
以上でWebサイトの表をExcelスプレッドシート形式で取得するアクションの設定は完了です。
取得したExcelシートは%ExcelInstance%という変数に格納されるので、この後のアクションで%ExcelInstance%の内容をファイルに保存したり、一覧の内容を分析して集計や繰り返し処理を行ったりすることなどが可能です。
Excelデータをファイル名を指定して保存するアクションの設定
今回のサンプルでは、取得した一覧をExcelスプレッドシートに格納した後、その内容を任意のファイル名で保存できるようにしています。
ファイル名を指定してExcelデータを保存するには「ファイルの選択ダイアログを表示」アクションと、「Excelの保存」アクションを組み合わせて行います。
Excelデータをファイル名を指定して保存する手順
「ファイルの選択ダイアログを表示」アクションを配置し、設定ウィンドウの [ダイアログのタイトル] ボックスに任意のメッセージを入力します。ここでは例として「ファイルの保存」と入力しています。次に、[保存] ボタンをクリックして閉じます。
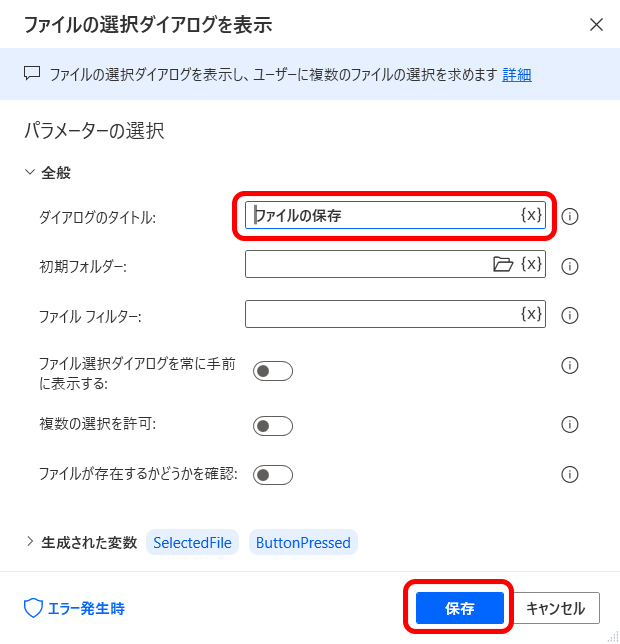
「Excelの保存」アクションを配置し、設定ウィンドウを開きます。
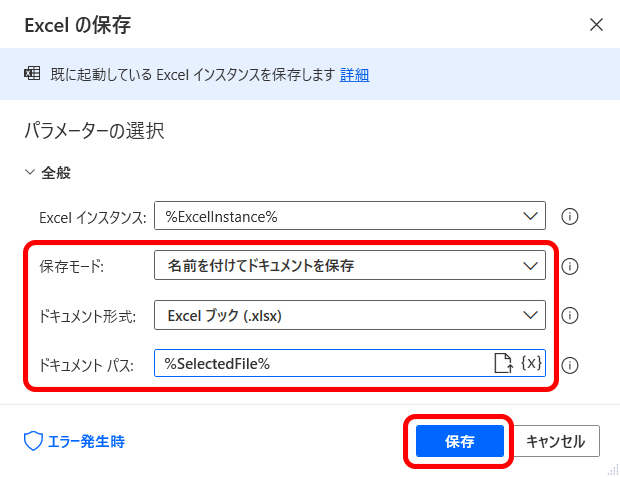
[保存モード] ボックスの一覧から「名前を付けてドキュメントを保存」を選択します。
[ドキュメント形式] ボックスの一覧から「Excelブック(.xslx)」を選択します。
[ドキュメント パス] ボックスで%SelectedFile%(「ファイルの選択ダイアログを表示」アクションで生成された変数)を指定します。
上記の設定が完了したら [保存] ボタンをクリックして閉じます。
以上でExcelのデータ(Excelインスタンス)をxslx形式のファイルに名前を付けて保存するフローは完了です。
実行するとファイルの保存ダイアログが表示され、指定した名前でファイルが保存されます。
以上で今回のサンプルの解説は終了です。こちらのフローを参考にぜひいろいろなアイデアを基に自動化にチャレンジしてみてください。
お読みくださりありがとうございました。今回の内容が少しでもお役に立てば幸いです。

コメント